开元棋盘财神捕鱼官网版下载2023 MLSQL:融合 Spark+Ray,让企业低成本落地 Data+AI
近日,由Kyligence主办的Data & Cloud Summit 2021行业峰会在上海成功举办。峰会特别设立了“开源有道”分论坛,邀请了Apache Kylin、Apache Spark、Alluxio、Linkis、Ray、MLSQL等开源社区的专家。技术大师就大数据、机器学习等多个热点话题分享了开源社区的前沿技术和最佳实践。 Kyligence技术合伙人、高级架构师朱海林分享了一站式大数据和AI平台MLSQL如何整合Spark+Ray帮助企业低成本实现数据+AI,引起了现场观众的热烈讨论。
以下为朱海林会议发言实录
大家好,我叫朱海林。今天我很高兴向大家介绍一站式大数据和AI平台——MLSQL。这里大家基本上都是做大数据相关的工作。无论你的公司是否已经在使用人工智能,我们都知道人工智能的实施只是时间问题,因为大数据和人工智能有着非常强大的持续关系。 MLSQL 所做的事情其实很简单——它让每个人都能以低成本实现数据和人工智能。今天我们简单介绍一下以下四点:
01
当前数据+AI落地面临的痛点
目前的痛点主要分为两部分。首先是企业面临的痛点;二是一线人员,即AI落地人员面临的痛点。
我们来看一下中小企业开发算法的典型流程:
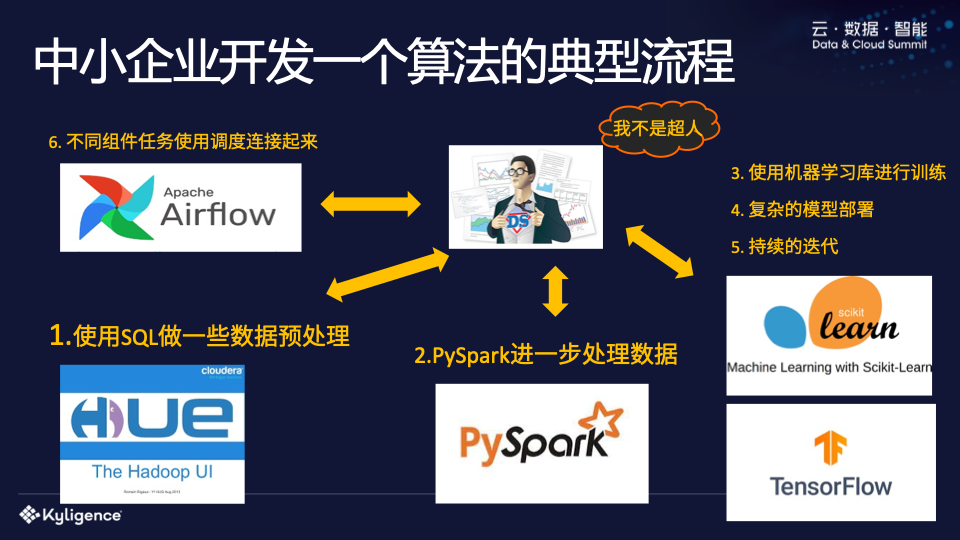
第一步是执行数据提取。企业数据往往分布在各个地方。如果企业数据仓库做得好的话,可能会把数据放在HDFS上,使用HUE,在HUE上写SQL进行数据提取和预处理。但SQL的功能毕竟有限。你会发现很多复杂的函数是SQL无法处理的。
这个时候有的公司会引入PySpark,使用Python来处理。 PySpark处理完数据后开元棋官方正版下载,可能还需要一个机器学习库,比如TensorFlow等,如果是分布式的,可能还需要将TensorFlow放在专门的Cluster集群中来运行。当然,企业也可以放入PySpark中运行,但是大家会发现,通过PySpark将数据“喂”到机器学习库是很困难的。
例如,如果算法是单机版本,Pyspark是分布式的,那么最终需要将数据收集到driver并交给TensorFlow,或者在worker节点上执行Repartition,然后将数据交给TensorFlow。在向驱动程序收集数据的过程中很有可能会挂掉,因为数据可能有几千万甚至上亿。如果Repartition是对一个分区进行的,你会发现进行了一次大的shuffle,这种表现也可能会导致Spark挂掉,这也是PySpark现在不能很好处理这个问题的原因。
完成上述步骤后开元ky888棋牌官方版,还需要部署这个模型,大多是作为API服务,通常有以下三点:
以上是模型训练后通常应用的三点。
在完成数据预处理、使用PySpark处理数据、使用机器学习库进行训练以及复杂的模型部署之后,企业仍然需要继续迭代。大家都知道模型会随着数据的变化而变化。如果我们不继续迭代,我们辛辛苦苦训练出来的模型可能在一个月后就变成了一堆垃圾。数据变了,人们使用数据的习惯也变了。没有不断的变化,模型如果不不断的更新和迭代就毫无用处。
你会发现越来越多的组件需要维护。为了让整个任务运行起来,大家都会使用调度任务来进行调度。例如,如果你在HUE中运行一个任务,由于它们都属于不同的系统,因此很难实现资源的灵活分配和充分利用,你会发现越来越多的问题。
对于数据科学家来说,为了实现一个算法,需要学习那么多框架,而这些框架与自己的工作相关性并不高。数据科学家不是超人,所以实现算法的门槛会变得非常高。高的。
一线工作者的痛点

一线人员包括研发人员、数据科学家和管理人员。你会发现在这个过程中,部署和维护的成本是非常高的。数据会在各个组件之间流动,这可能会导致数据安全问题。数据需要多次写入磁盘,格式和形状不一致,并产生大量临时文件。这些文件很可能位于不受控制的目录中,这可能会导致数据泄漏。人们常常会“选择性地忽略”这些文件,尤其是从事研发的朋友。每个人在使用时都很高兴,但常常忘记清洁它们。
当然,在这个过程中,也存在着资源浪费的问题。每个组件都会占用资源,你没有办法让系统灵活协调资源。其次,存在使用门槛高的问题。例如,如果一个数据科学家想要实现一个算法,他需要学习Python以及上面提到的各种系统和框架。
从上面的描述中你会发现,一个算法在中小企业的实施可能需要数周的时间,需要一个算法工程师的投入和多次研发。最终,实现一个算法可能需要一周、两周甚至一个月的时间。
企业实施数据+AI的痛点
企业现在如何利用人工智能?理想的情况是:一个算法提高1%的效率,降低大量成本,公司多赚1亿。然而,这种情况实际上是非常罕见的。一般来说,只有在大型企业中,效率提高1%才能带来这么大的利润。但大多数中小企业、互联网公司其实都是由很多场景组成的。每个场景可能需要一种或多种算法,而这些算法往往体现在流程优化、用户体验提升等方面。
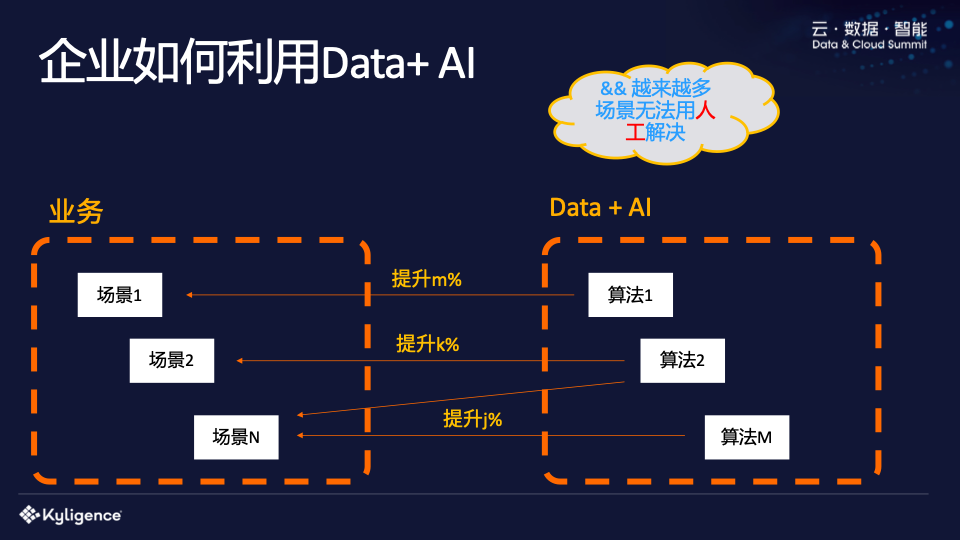
如上所述,乐观地讲,实现一个算法需要一周的时间。现在普通的中小企业往往有上百个场景,需要实现成百上千种算法,并且需要不断迭代。大家可想而知,这成本有多高。同时,对于企业来说,这些消耗大量人力物力的算法所带来的效益是难以量化的。困难在于这些场景无法手动解决,只能通过AI来解决。
我经常举的一个例子是“在线咨询”。在线咨询过程中有一个分诊环节。当用户描述他的症状时,需要将他分配到特定的部门。对于其背后的公司,成千上万的用户同时在询问。这种情况下没有办法手动完成,只能通过算法。如果98%的分诊能够在机器的帮助下完成,那么大多数用户的体验将会得到极大的提升。但对于企业来说,他们带来的价值只是一小部分产品的良好体验。
痛点一:算法实现成本高于收益

对于企业来说,往往存在两大痛点。企业会发现,在特定场景下实施某种算法时,成本远高于收益。正如我们刚才提到的,这个算法可能只会带来一点体验上的提升,但公司却投入了多名算法工程师,花了几周甚至一个月的时间来实现。对于企业来说,算法工程师和研发工程师的资源比较珍贵,硬件成本也比较高。
痛点二:人力资源不足、时间成本高

第二个痛点是,有些企业特别有远见,不关心资本投入。他们的目的是让自己的产品领先于其他公司,即使前期亏损。尽管投入了这样的资金,企业也未必能够成功实施数据+AI。首先,企业需要招聘大量的研发人员、数据科学家等,即使投入大量资金,也可能会很困难。尤其是对于一些非技术型企业,比如传统制造业,更是困难重重。即使公司招人了,基于之前的平台体系来搭建还是非常困难的。建设实施可能需要半年到一年的时间,时间成本非常高。
以上两个痛点给大多数企业实施数据+AI带来了诸多挑战。
02
MLSQL 到底是什么?
对于广大想要实现数据+AI的企业来说,不妨考虑一下MLSQL。首先我们来了解一下什么是MLSQL,然后我们来理解为什么它可以解决上述问题。我们将 MLSQL 定义为一种语言。语言通常由两部分组成。一是语言的规范和语法,二是语言的执行。一种语言只有在有规范的情况下才有用处。书面语言需要一个引擎来执行它。
为了更好地拥抱AI生态,我们实际上使用了两个引擎,一个是Spark,另一个是Ray。在座的很多人应该都从事大数据工作,并且应该熟悉 Spark。如果你使用过Spark,通常会使用UDF。不知道你有没有想过解决这个问题:我用Python训练了一个Tensorflow模型。是否可以将这个模型做成UDF,直接放入SQL中使用?这样就可以做批处理、流处理,甚至暴露为API来提供外部服务。传统上我们可能不得不使用JNI,因为Spark是用Java或者Scala开发的,而大多数AI模型都是基于Python/C++开发的,所以这个过程会比较麻烦。
MLSQL 已经做了一些工作来在 Ray 上运行 Spark 的 UDF。用户自己无意识,正常注册自己的UDF即可。这项工作我们已经取得了初步成果。我们可以用96行代码将任何需要的模型预测功能(基于Python开发的模型)封装成Spark UDF模型。这在以前是很难的,因为之前UDF是无状态的,但是模型预测是有状态的,所以需要提前加载一个模型,然后提供UDF预测能力。我们通过整合Spark+Ray很好的解决了这个问题,所以两者的整合可以带来很大的想象空间。
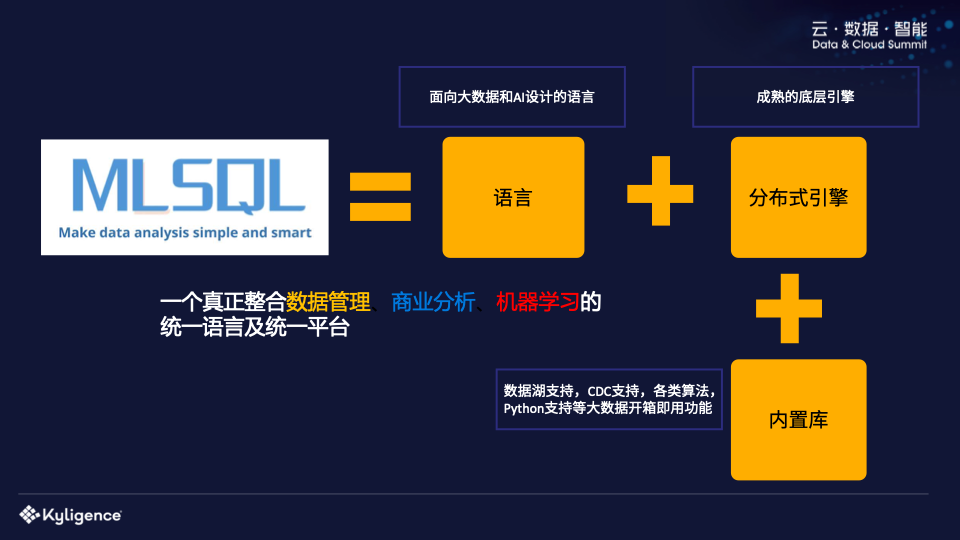
MLSQL的核心引擎是Spark,Ray是可插拔的。两者都是分布式的,连接也是分布式的,所以我们说MLSQL天然就是一个分布式引擎。对于企业来说,如果只有语言和执行引擎,没有第三方开箱即用的库,一切都必须自己开发,其实价值不大。为了帮助企业更好地实现数据+AI,MLSQL提供了很多功能的支持:
下面我将展示一个Demo。在Demo中,用户完全不需要使用Python。他们仅通过SQL就可以完成复杂的机器学习过程:从提取数据、处理数据、训练数据、调整参数,最后部署到API中。服务和 UDF。
当然,MLSQL也支持Python。在MLSQL中,Python是一个文本脚本。可以在Spark中处理数据,或者在Python中分布式进行模型训练,结果返回到Spark,中间不需要登陆,性能不错。由于 Python 部分也是分布式且灵活的,这得益于我们对 Ray 的支持。除此之外,我们还可以实现一些非常酷的效果,比如前面提到的使用Ray作为Spark UDF的执行引擎,完成Python模型到UDF的转换。
传统SQL默认需要指定数据源。例如,Hive是数据源。当你编写 select 时,系统知道从哪里获取它。但事实上,数据联合查询才是未来。主会场老板也提到,未来的数据一定是从采集到连接,为什么?如今,法律法规对数据隐私的要求越来越严格。各地数据不能随意传输。如果需要进行统一分析,就必须采用联邦的方法。未来数据仓库将仅作为数据源之一。你会有很多数据仓库,它们物理上是分开的开元棋盘app官方版下载_开元棋盘app官网版下载-跑跑车,上层视角可能还是数据仓库的概念。
MLSQL提供了很好的便利。例如,在上面的例子中,MLSQL可以加载Hive数据、JDBC数据和HDFS数据。加载完成后,该表就可以直接使用了。 MLSQL对SQL做了更好的修改。选择后,立即可以得到一个视图名称,如下图的join。最后我们就可以得到一个最终表,并从最终表中取出一个输出结果。你会发现我们的SQL完全是脚本化的,使得它非常简单。没有必要写非常复杂的嵌套SQL,因为SQL的复杂性来自于两个方面:
子查询会导致复杂的嵌套。嵌套一定不符合人类的思维。只有顺序结构才符合人类思维。
连接查询和窗口。有时一条 SQL 有数百或数千行。原因只是使用了大量的子查询和连接了无数的表。 MLSQL在这里可以完全扁平化它。选择后,您将得到一张桌子。使用起来非常简单。
此外,MLSQL还提供分支语法支持和模块支持,使SQL更强大、更方便。
MLSQL 原理
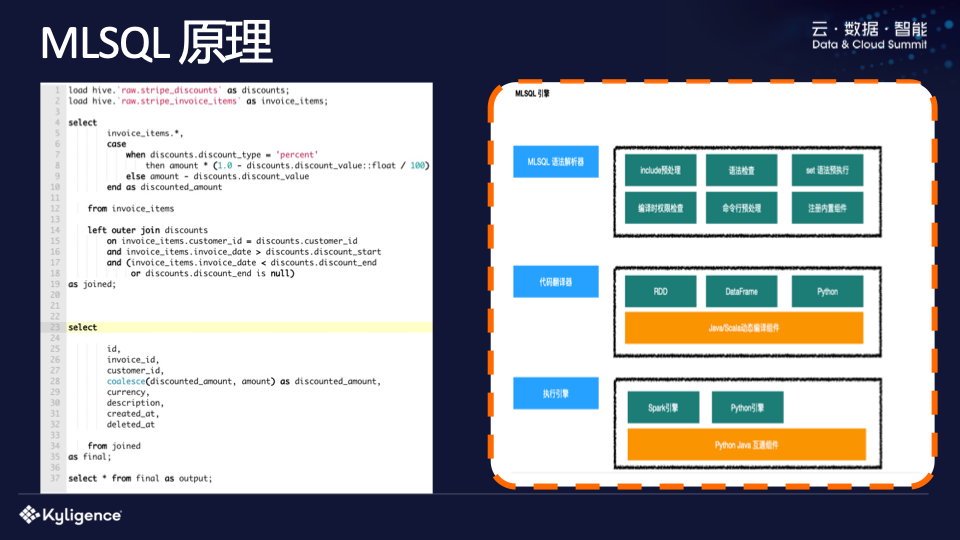
上图右侧为示意图。 MLSQL主要做了三部分:第一是语法解析,第二是代码翻译器,第三是执行引擎。更重要的是语法解析引擎。 MLSQL 确实包含处理并支持模块化。虽然看到的是SQL,但是现在可以直接使用MLSQL来开发一个模块,最后通过include语法引入。
我们之前使用 MLSQL 开发了一个名为 lib-core 的标准库。用户可以直接包含它来完成一些特定的功能,包括语法检查、执行编译时的权限检查以及一些命令行预处理,然后是一些内置组件相关的初始化。
解析后,MLSQL会将其翻译为RDD数据框或Python代码。以前写UDF比较痛苦的是需要开发jar包,部署时需要重启Hive Server。在MLSQL中,可以使用register语法来动态注册UDF,在其中编写一段Scala代码,然后在后续的SQL中直接使用。这是因为MLSQL有一个针对Scala和Java的动态编译组件,其中嵌入了一段Python代码。它由Pyjava互操作组件完成,最终支持在Java中执行Python代码,从而在SQL中实现Python。并实现数据互操作。
MLSQL 架构
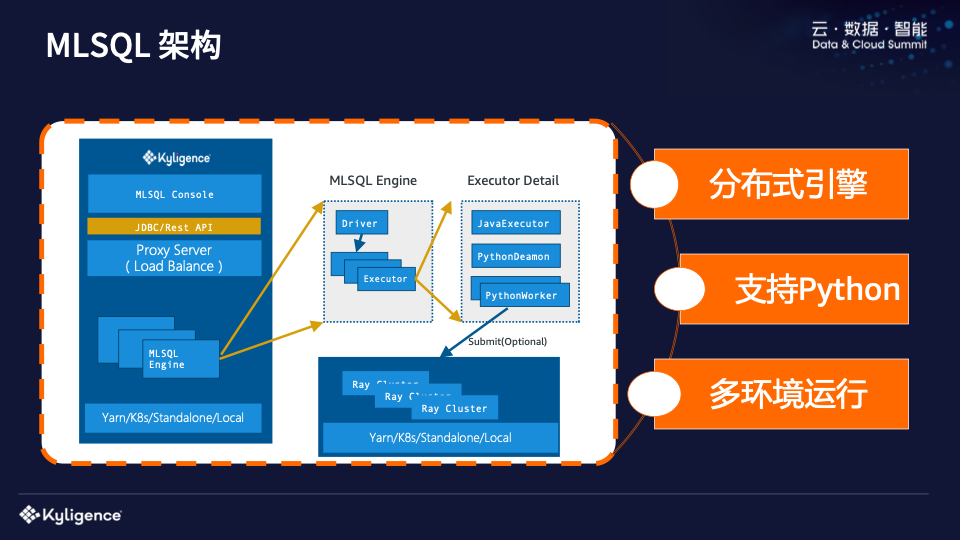
接下来我们介绍一下MLSQL的架构,非常简单。作为一个引擎,前面会有一个Load Balance,再加上JDBC/Rest API,最后会有一个控制台界面供你使用。 MLSQL 可以在 Yarn/k8s/Standalone 和 Local 模式下运行。 MLSQL Engine是典型的主从结构。因为我们支持Python脚本,这就意味着我们需要在Java中执行Python代码,所以我们重新实现了一套Python Deamon和Python Worker,它们作为Client,然后在Ray中执行Client代码,大致等价Yu在PC上编写了一段Python代码,最终会连接到Ray的Cluster上执行。
传统的 PySpark 有一个大问题,您可能也遇到过。 Python Worker 和 Java Executor 是在一起的。这种混合架构存在一个问题。如果你运行一个大的查询,Python Worker会占用非常大量的内存,或者你的CPU会被占满,你没有办法隔离资源。当它满了的时候,HDFS也在上面运行。如果不小心把节点跑掉了,还可能会遇到数据安全问题,Python Worker节点也无法通讯。所以这种混合架构其实是有问题的。 MLSQL 实际上缓解了这个问题。真正的Python处理逻辑会自动发送到Ray Cluster执行。多种环境不再是问题。以前,Python工作者可能需要TensorFlow A版本,而另一个用户说我想要TensorFlow B版本。这种情况下,我们可以设置多个Ray Cluster,由用户直接决定连接哪个Ray Cluster,问题就轻松解决了。
总结起来,MLSQL架构其实有以下三个特点:
无论是SQL引擎还是Python引擎,几乎每一步都是分布式引擎;
MLSQL支持Python,拥抱AI生态,解决数据连接问题;
支持多种环境,因为在真正的机器学习中,你会发现环境是最难解决的问题。

MLSQL 实际上面向非常广泛的受众。它是一种非常简单的语言,只能使用SQL;但它也可能很复杂,允许您编写一些高级 Python 代码来与 SQL 协作;同时,作为研发工程师,您可以开发UDF功能或编写一些插件模块来增强MLSQL语言和引擎。 MLSQL是一个插件内核,可以处理数据科学家、大数据工程师、产品和运营等,而且也是面向服务的。这些将在下面的案例场景中简要介绍。
03
如何利用MLSQL低成本实现数据+AI
MLSQL 是如何做到这一点的?我认为正是开源、统一、简单、安全这四点,让企业能够真正低成本地实现数据+AI。

开源

首先,MLSQL是开源的,可以部署在云端和云端。开源社区有保障。未来我们还将提供商业版本支持。您可以选择开源或商业版本。

我们不仅开源了引擎,还开源了开箱即用的 MLSQL Console,它是一个 Web IDE。 MLSQL还可以让单引擎支持多租户,Web IDE支持Script/Notebook开发模式。我们还提供非常高端的分析车间,可以实现自助分析。 MLSQL 可以做到。您编写的任何复杂的 SQL 都可以在分析研讨会中使用“一点一点”的方法完成。这在过去很难做到,因为你必须将复杂的操作转换为 SQL 语句。事实上,没有工程师能够做到这一点。然而,在MLSQL中,任何用户操作都可以转换为一条语句,最终形成数千行。 MLSQL代码只需要一个前端工程师即可完成。
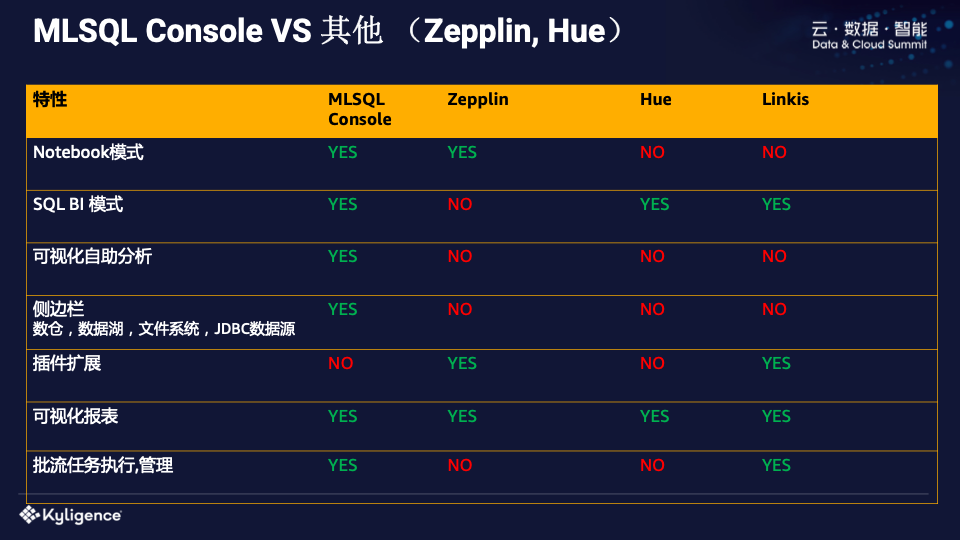
最后我们来看看Console、Zepplin、HUE的对比。
统一
其次,MLSQL实现了统一。对于用户来说,不再需要那么多的组件来完成大量的工作。语言层和交互层是统一的。引擎层是引擎。你解压并部署它,整个工作就统一了。完毕。

下图简要比较了 MLSQL 与其他语言(例如标准 SQL 或 PySpark)相比的优缺点。
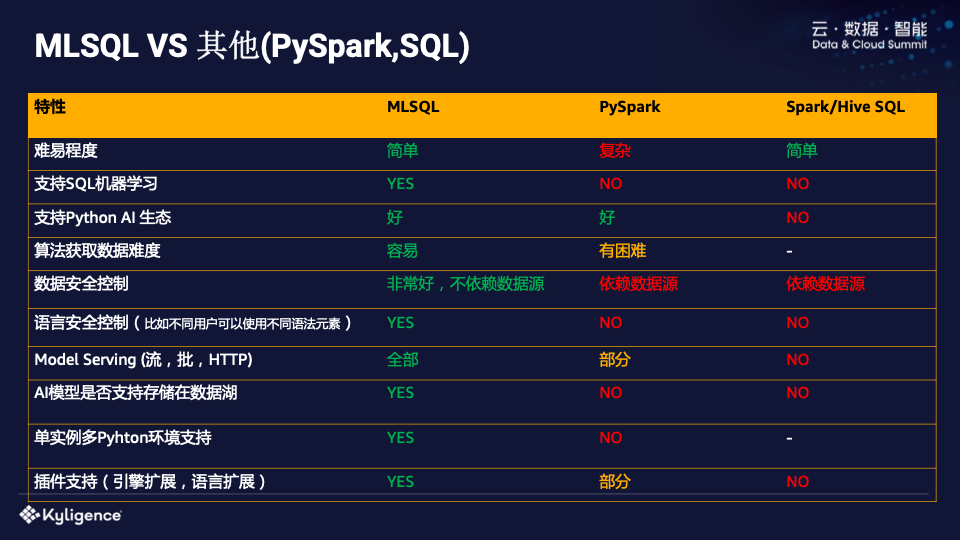

统一的价值在于它带来更低的成本。无论是对于维护者还是用户来说,大家都告别了一堆系统和组件。
简单的
MLSQL 的另一个价值是简单性。

我们测试过,发现如果你会SQL,几天之内就可以上手,并且可以做一些批量流式处理和数据分析工作。如果你是一个标准的数据科学家,你可以在里面完成一整个Pipeline,让你可以写Python。最重要的是,你可以轻松地自动生成代码来创建一些高端产品。比如我们前面提到的无代码分析工坊,与其他技术相比,如果你使用MLSQL来做同样的事情,你会发现它不是一个数量级的工作。 “简单”的价值在于降低了用户操作的门槛,提高了一线人员的效率,以前只能用Python才能完成的任务现在可以用SQL来完成。
安全
MLSQL 还带来了安全价值。以前大家都会用Ranger或者其他一些组件。有了这些组件,你会发现最大的问题,它们会侵入底层数据存储。一个典型的例子是我使用Pyspark访问MySQL数据库。如果有1000人访问,数据库人员需要给这1000人分配JDBC权限才能连接,这显然是不可能的。
MLSQL是一种自主开发的语言。我们在设计这种语言的时候就考虑到了数据访问安全控制的问题。因此,MLSQL可以在语言层面实现权限统一,可以控制用户是否可以加载某些数据,粒度是表级还是行列级。这些都可以在 MLSQL 引擎级别完成,而根本不需要侵入各个存储层。是否可以访问Hive并不是Hive授权的,而是在语言交互层面已经授权的。

与其他语言相比,MLSQL也有很大的优势。它不仅可以控制数据访问,还可以在语言层面上授权一定的语法。例如,在Python中,你绝对无法控制使用哪种语法,除非你再次实现它。但在MLSQL中,是否可以使用自定义UDF、是否可以使用Python、是否可以使用某个模块都可以用于非常精细的权限控制。
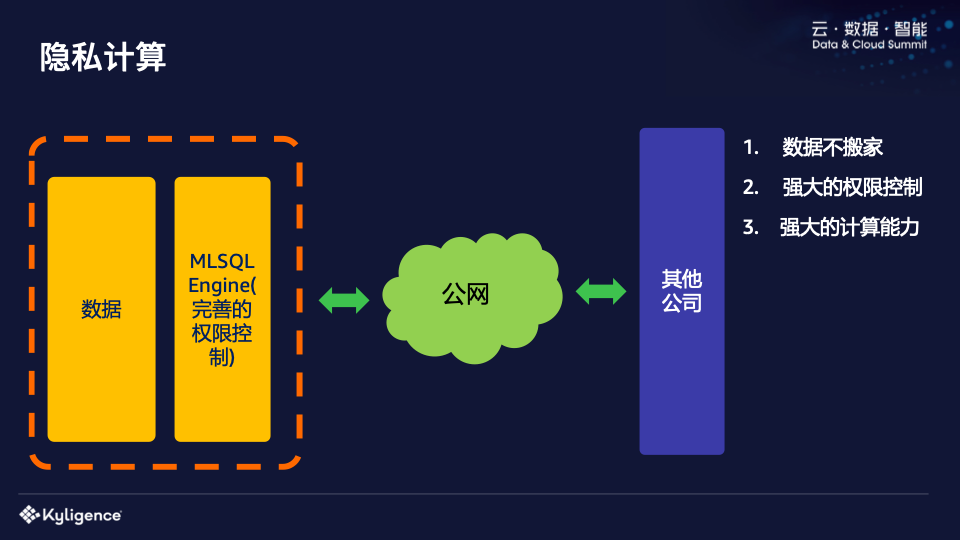
还有刚才提到的隐私计算。现在不允许移动数据。例如,A公司和B公司合作时,两者的数据不能移动。之前为什么需要移动呢?之前没有什么好的办法来公开这些数据。为什么?以前如果将SQL暴露出来,根本无法满足用户分析的需求。但如果Python等API暴露出来,那就太灵活了,根本没有安全性。
正如我们前面提到的,MLSQL不仅可以控制数据安全,还可以控制语法元素,非常灵活。这意味着你可以提供一套MLSQL引擎接口,你可以在其中随意“玩”,生成算法模型。该模型经A公司授权即可下载至B公司,不存在授权安全问题。 。
04
MLSQL典型案例
接下来我们看一下MLSQL的几个典型案例。
案例1

首先我们看场景一,这是一家消费金融公司。他们关注 MLSQL 已有 3 年,运行了超过 700 万个任务。数据规模为TB。公司现有200多人,200人中已经注册了35%。 MLSQL使用账号,即70人以上注册账号。日活跃度达到71%,这意味着70名注册人中,每天有近50人使用。
通过这个案例,你可以发现使用MLSQL玩转数据的门槛很低,人人都会用。更夸张的是,整个大数据平台支撑团队只用了两个人,不需要复杂的组件就可以完成很多事情。这告诉我们什么?这意味着维护平台的成本非常低。
案例2
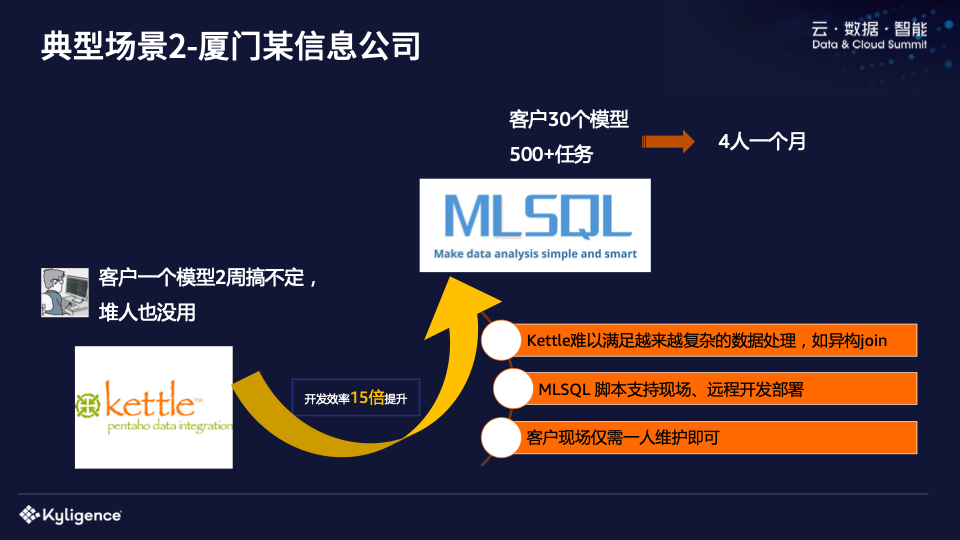
另一个典型场景是厦门的一家信息公司,为政府部门提供服务。比如PPT中提到的模型,查找卡口处是否有汽车甲板,也就是数据进来后,我需要计算它是否出现在不同的地方。对于这些模型,他们曾经使用 Kettle 来制作。他们会发现客户的模型无法在两周内完成。这个时候他们就不能加人了,因为加人是没有用的。后来他们实在受不了了,随着数据源越来越多,没有办法对异构数据进行联合查询,于是就引入了MLSQL。
引入MLSQL后,他们的开发效率提高了15倍。你是怎么计算的?他们举了一个例子。通过MLSQL为客户提供支持后,四个人花了一个月的时间实现了30个模型和500个任务。客户现场只需要一个人,每天只需要看一眼即可。从日志和异常来看,无论是开发效率还是运维效率都有非常明显的提升。而且,他们之前的工艺都是在本地开发,然后在客户现场调试。如果出现问题,他们就必须返回“大本营”。现在MLSQL本身就是一个脚本,可以直接在客户现场调试。 MLSQL 的成本非常低。 ,其自身的语法是可扩展的,还可以使用插件来实现更复杂的处理逻辑。
这是一个简单的演示
在Demo中可以看到,当我们将其部署为API服务时,你会发现它在进行预测时也会写SQL,但数据不再是一张表,而是你传过来的Json数据。我们可以把这个SQL应用到你传入的数据上来执行计算。无需任何开发,通过组合一些功能就可以完成端到端的预测,而传统预测必须提供向量来预测。
我们刚才看到的寄存器可以在服务上运行,并且是一个标准函数。包括我们之前的案例和demo演示,因为都是内置的模型,所以这个很容易做到。现在通过与Ray结合,MLSQL还可以将Python模型变成UDF函数来使用。
正如你所看到的,一个算法的开发和发布已经成为一件非常简单的事情。从数据加载和处理到训练模型、参数调整、发布为API服务,整个过程都可以在Notebook中完成。我们需要培养“爸爸”。完成后,我们可以将其发送给第三方播放。
如需获取演讲视频和PPT信息,请扫描下方二维码。

关于跬智
Kyligence 由 Apache Kylin 创始团队创建,致力于打造下一代智能数据云平台,为企业实现自动化数据服务和管理。基于机器学习和人工智能技术,Kyligence 从多云数据存储中识别和管理最有价值的数据,并提供高性能、高并发的数据服务来支持各种数据分析和应用,同时不断降低 TCO。 Kyligence 已服务中国、美国及亚太地区多家银行、保险、制造、零售等客户,包括中国建设银行、上海浦东发展银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、一汽、安踏、百胜、歌诗达、瑞银、大都会人寿、AppZen等全球知名企业和行业龙头。公司已通过ISO9001、ISO27001、SOC2 Type1等各项认证和审核,在全球拥有众多生态合作伙伴。

 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论